The phrase marginal cost of AI tokens vs. human labor sounds like something that belongs in a graduate economics seminar, but the idea is surprisingly practical. It is really asking a simple question: once the system already exists, how much does it cost to do one more task with AI compared with one more task done by a person?
That question matters because AI changes the cost structure of work. A business that once paid people by the hour to draft, summarize, classify, translate, outline, or answer routine questions can now buy those activities in tiny units called tokens. Sometimes the difference is not just big. It is comically big. A small AI text task can cost fractions of a cent, while five minutes of human labor can cost a few dollars before benefits, management time, training, and overhead.
But that does not mean humans are obsolete, and it definitely does not mean the cheapest output is the best output. The real lesson is more interesting: AI makes low-stakes, repeatable language work extremely cheap at the margin, while human judgment becomes more valuable in places where trust, taste, accountability, context, and relationships matter.
What Marginal Cost Means in Plain English
Marginal cost is the cost of producing one more unit. If you run a bakery, it is the cost of one more loaf of bread after the oven, rent, recipes, and staff are already in place. If you run a software company, it is the cost of serving one more user or processing one more request. If you use an AI model through an API, it is often the cost of the extra input and output tokens required for one more response.
This is different from average cost. Average cost spreads everything across all output: training the model, building the product, hiring engineers, managing servers, writing policies, supporting customers, and paying for failures. Marginal cost asks a narrower question: after the setup is done, what does the next run cost?
That distinction is the reason AI feels so economically disruptive. Human labor is usually lumpy. You hire a person, schedule their time, train them, manage them, and pay wages. AI tokens are granular. You can buy a few hundred tokens for a tiny task, a few thousand for a longer answer, or millions for a large workflow. The unit of work gets sliced much smaller.
How AI Token Pricing Works
AI systems do not usually charge by the sentence or paragraph. They charge by tokens, which are small pieces of text. A token may be a word, part of a word, punctuation, or spacing depending on the language and tokenizer. When you send a prompt, those are input tokens. When the model replies, those are output tokens. Many API pricing pages list separate prices for input, cached input, and output tokens.
OpenAI’s current API pricing page lists model prices per one million tokens. As of this article, GPT-5.5 standard short-context pricing is .50 per million input tokens, .25 per million cached input tokens, and .00 per million output tokens. GPT-5.4 is lower, and smaller models such as GPT-5.4 mini and GPT-5.4 nano are lower still. Those numbers can change, so the source page is worth checking whenever you are doing serious budgeting.
The key idea is that output tokens usually cost more than input tokens. If you ask for long answers, verbose summaries, or multiple drafts, your costs rise. If you keep prompts tidy, reuse cached context where appropriate, and ask for concise output, the marginal cost falls. This is why prompt design and product design are also cost design.
A Simple Cost Comparison
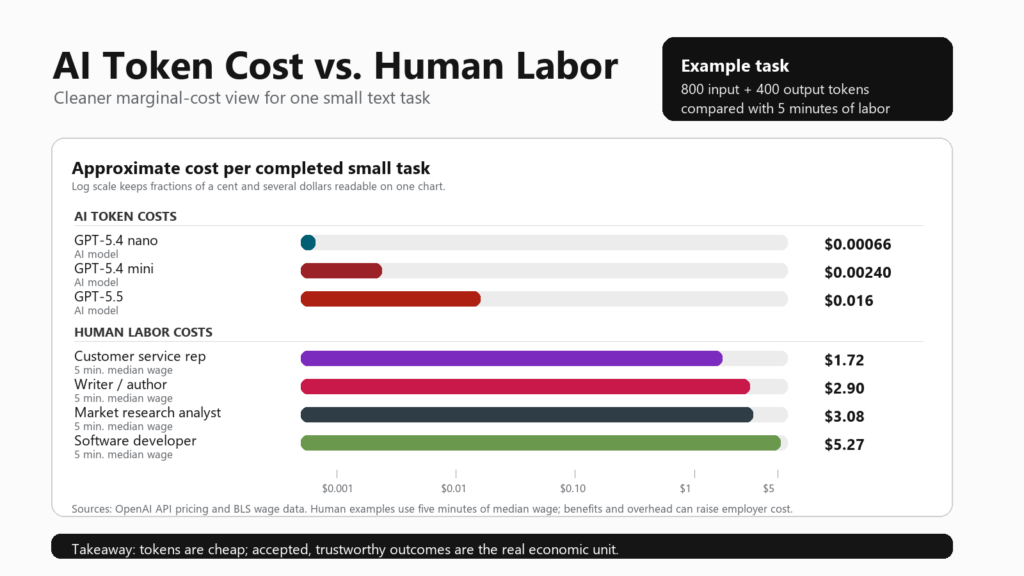
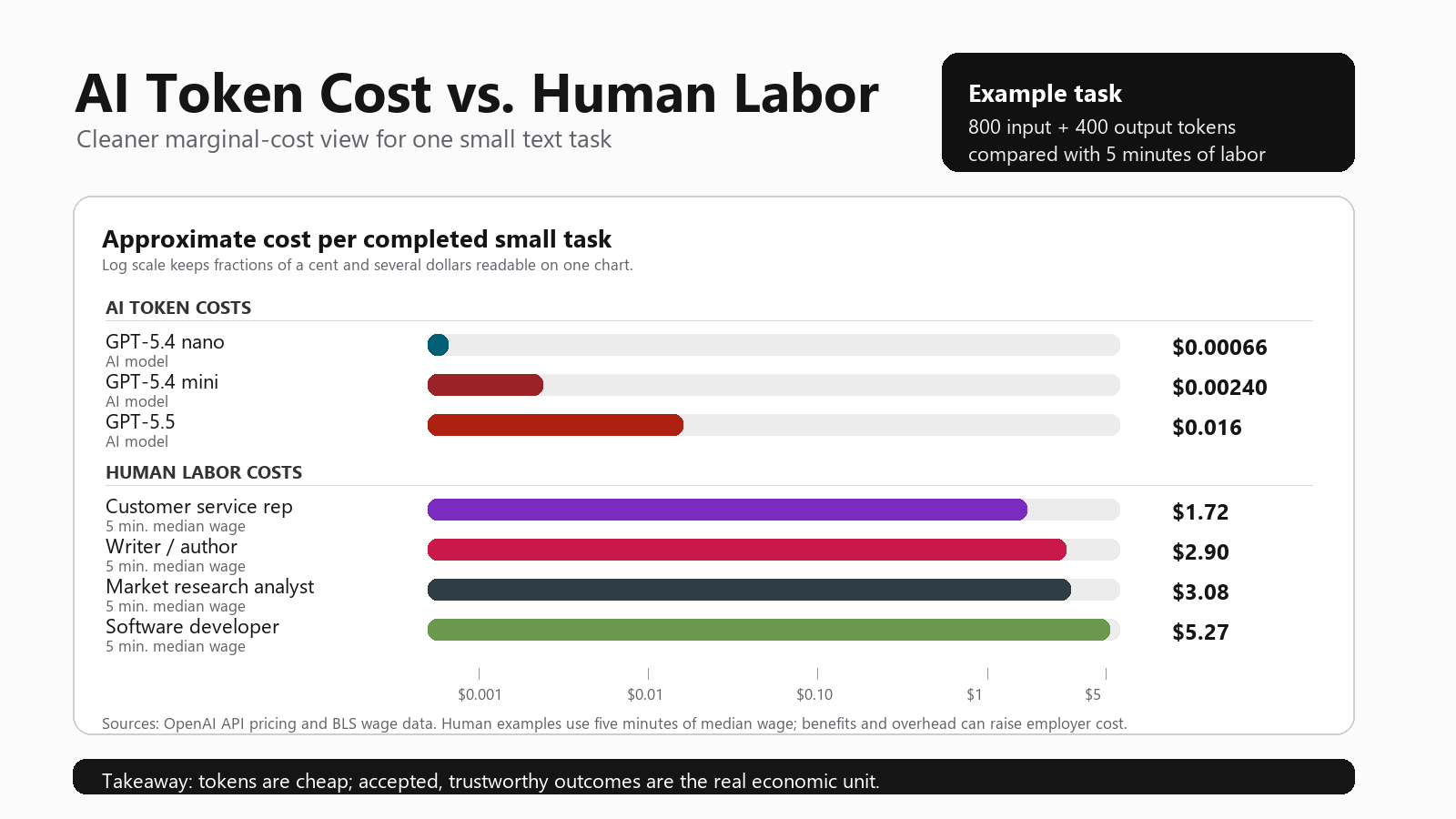
Let us compare one small text task. Imagine a request that uses about 800 input tokens and produces about 400 output tokens. That might be enough to summarize a customer email, draft a short reply, classify a support issue, outline a blog section, or explain a basic concept.
For the human side, compare that to five minutes of paid work. Five minutes is not a full task in every job, but it is a useful everyday unit. A person can often spend five minutes reading, thinking, replying, checking details, or cleaning up a draft.
| Example | Cost basis | Approximate marginal cost |
|---|---|---|
| GPT-5.4 nano | 800 input + 400 output tokens | .00066 |
| GPT-5.4 mini | 800 input + 400 output tokens | .00240 |
| GPT-5.5 | 800 input + 400 output tokens | .01600 |
| Customer service representative | 5 minutes at BLS median hourly wage | About .72 |
| Writer or author | 5 minutes at annual median wage divided by 2,080 hours | About .90 |
| Market research analyst | 5 minutes at annual median wage divided by 2,080 hours | About .08 |
| Software developer | 5 minutes at BLS median hourly wage | About .27 |
This table is not saying the AI output is equal to the human output. It is saying the direct marginal production cost can be dramatically lower. On a pure token bill, a small GPT-5.5 task might cost around 1.6 cents. A smaller model might cost far less than a penny. Five minutes of human time, meanwhile, can range from a couple dollars to several dollars before benefits and overhead.
Benefits widen the gap. In the BLS Employer Costs for Employee Compensation release for September 2025, private industry employers averaged .37 per hour for wages and salaries plus .68 for benefits. That is .05 per hour in total compensation. Benefits do not apply the same way to freelancers or contractors, but for employers they are part of the real labor cost.
Why the Token Bill Is Not the Whole Cost
The cheapest token is not automatically the cheapest business decision. AI has hidden costs, and some of them are easy to overlook when the API bill looks tiny.
- Review cost: someone may need to check the answer for accuracy, tone, compliance, or brand fit.
- Failure cost: a wrong answer in a low-stakes draft is cheap; a wrong answer in legal, medical, financial, or safety-sensitive work can be expensive.
- Integration cost: businesses still need software, workflows, monitoring, security, and user training.
- Context cost: AI may need documents, examples, policies, or customer history to do useful work.
- Trust cost: customers may accept automation for simple requests but prefer humans when emotions, money, or accountability are involved.
That is why the best metric is not simply cost per token. It is cost per accepted outcome. If ten cheap drafts produce one usable response after heavy editing, the true cost includes the review time. If one human expert solves the problem correctly in three minutes, the higher hourly cost may still be the better bargain.
Where AI Tokens Beat Human Labor
AI’s marginal cost advantage is strongest when the work is language-heavy, repeatable, low-risk, and easy to verify. Examples include summarizing long documents, turning notes into a first draft, creating outlines, generating alternative headlines, classifying routine support tickets, extracting fields from text, translating simple internal notes, and rewriting a message in a different tone.
These are tasks where the first version is often the bottleneck. People spend a surprising amount of time getting started: staring at a blank page, rewriting the same paragraph, summarizing the same meeting, or cleaning the same customer emails. AI can reduce that friction. It makes the first draft cheap enough that you can ask for three versions, pick the best one, and refine it.
That changes how work feels. A manager may stop asking, “Is this worth writing?” and start asking, “Is this worth reviewing?” A student may stop thinking, “I have no idea where to begin,” and start thinking, “Which outline is strongest?” A small business owner may use AI to draft product descriptions, social posts, FAQ answers, and email templates without hiring a writer for every tiny item.
Where Human Labor Still Wins
Humans still win when the work requires lived context, judgment, accountability, empathy, negotiation, taste, strategy, or responsibility. AI can write a polite apology, but a real customer may need a real person to own the problem. AI can generate code, but a developer still needs to understand the system, make tradeoffs, test behavior, and be accountable for the result. AI can summarize market research, but a good analyst knows which caveats matter and which signals are noise.
This is the mistake in many “AI vs. humans” debates. The question is not whether a token is cheaper than a minute. Of course it is. The question is whether the AI output is good enough for the situation, and what kind of human work remains around it.
In practice, AI often changes the shape of work instead of deleting it one-for-one. A writer becomes more of an editor and strategist. A customer service team spends less time on simple answers and more time on angry, complex, or high-value cases. A developer may spend less time typing boilerplate and more time reviewing architecture, tests, security, and user experience.
The Economics of Cheap Attempts
One of the biggest economic changes is that AI makes attempts cheap. When human labor is expensive, we conserve attempts. We do not ask someone to write twenty versions of a headline unless the project matters. We do not ask a staff member to summarize every meeting three different ways. We do not explore every possible customer email variation.
With AI, the cost of trying more options falls. That can improve quality when people use it thoughtfully. You can ask for a plain-English version, a more formal version, a shorter version, and a version for beginners. You can compare them, combine the best parts, and still spend less than a minute of many professionals’ time.
But cheap attempts can also create noise. If an organization generates more drafts than anyone can review, it has not solved a productivity problem. It has created a review bottleneck. The smart move is to automate the boring first pass while protecting human attention for choices that actually matter.
What Businesses Should Measure
If you are deciding whether to use AI for a workflow, do not stop at the token price. Build a simple scorecard:
- How many tokens does one task usually use?
- How often is the first answer accepted without edits?
- How much human review time is required?
- What is the cost of a bad answer?
- Does the task require empathy, accountability, confidential context, or expert judgment?
- Can a smaller, cheaper model do the job well enough?
- Can prompt caching, concise output, or batching reduce cost?
The winners will not be the companies that replace every human with the cheapest possible model. The winners will be the ones that match the tool to the task. Use inexpensive tokens for reversible, repeatable, low-risk work. Use human judgment for decisions where being wrong is costly or trust is central.
The Bottom Line
The marginal cost of AI tokens is tiny compared with human labor for many text tasks. That is the economic engine behind the AI boom. When a short AI task costs pennies or fractions of a penny, people will naturally use AI for drafts, summaries, brainstorming, classification, and routine communication.
But the real comparison is not tokens versus people. It is cheap generation versus valuable judgment. AI lowers the cost of producing words, code, ideas, and options. Humans still carry the burden of deciding what is true, useful, ethical, tasteful, and worth acting on.
So the practical lesson is this: spend tokens generously where mistakes are easy to catch, but spend human attention carefully where the outcome matters. In the new economics of AI work, tokens are cheap. Trust is not.
For related reading, see How People Feel About AI Today, How to Use ChatGPT-5 for Personal Budgeting, and the Economics section.
Sources and Further Reading
- OpenAI API Pricing
- BLS Occupational Outlook Handbook: Software Developers
- BLS Occupational Outlook Handbook: Writers and Authors
- BLS Occupational Outlook Handbook: Customer Service Representatives
- BLS Occupational Outlook Handbook: Market Research Analysts
- BLS Employer Costs for Employee Compensation